


The time I vibe coded to solve music
Approaching the shuffle algorithm from a new perspective

If you have listened to music at all in your lifetime, you may have noticed one of the ongoing issues that both fuels the industry and also causes real issues with listening is: that the format and method of listening to music changes so rapidly.
In my lifetime alone, I have been exposed to vinyl, cassette, radio, cd, mp3, and now streaming in a 34 year time span. I have 119 vinyl records in my Discogs valued somewhere between $1,128.79 and $7,438.19. I purchased a large collection of cds in my childhood that I threw away stupidly when I changed cars to one without a cd player and thought I’d never go back. Since then I’ve been slowly rebuilding my cd collection through used cds on ebay and record stores because cds are cheap now, and you can still rip mp3s from cds.
At some point between cd, mp3, and streaming, we also had many variants of illegal music consumption as well, from Napster, Limewire, to blogs hosting torrent links and blogs hosting leaks of albums before they were available publicly. These could be imported into iTunes next to your other mp3s, but nobody paid for this.
After the illegal music boom, the music industry decided to legitimize and crack down so they could make money again, and this is why we have streaming services that allow unlimited access to all music distributed from artists worldwide in a way that is fairly accessible to most indie musicians and independent publishers to have their songs alongside big name artists. This was a major shift in accessibility.
However, there’s a problem.
The listening experience itself is lost. There is no nostalgia or discovery informed by listening data. Most people have not exactly been efficient archivists of their music library, and instead floating along and re-buying all of the music they’ve already purchased or stolen before. Putting the re-purchasing issue aside from a financial standpoint, which is frustrating enough on its own, let’s focus on the tedious task of rebuilding your library of artists every time you start with a new service. Having listened to various services over the years, Spotify’s current interpretation of my music taste is missing the key data that Spotify could be using to make me enjoy its product more, but it just doesn’t know anything about my past listening history to make accurate suggestions.
Shuffle is so repetitive it’s annoying.
Using Vibe Coding to solve this friction
So thinking about the issue from a design lens, let’s explore this in a way that can be improved through coding a solution. The main problem areas are as follows:
The current shuffle does not provide an enjoyable “True Shuffle” experience by providing seemingly non-random and preferential treatment. This is heavily documented in this community ideas page for Spotify: https://community.spotify.com/t5/Live-Ideas/All-Platforms-Option-to-have-a-true-shuffle/idi-p/4880594/page/188#comments
There is fragmented data that Spotify uses to create an enjoyable listening experience, and the algorithm will frequently suggest songs that are by artists that I am aware of and actively don’t like and already deliberately avoid
The listening experience itself is frustrating, because artists and songs are repetitively chosen in a way that seems preferential toward certain artists in a biased way
Spotify does not allow for multi-genre exploration, and forces you to listen in the same genre
Now, given these issues, I started exploring how to make a better experience. As a contributor to the Spotify community channel above, and a recipient of emails whenever other people suggest the same problem and solution, I feel validated that we are onto something with this being a real world problem.
I began to wonder, what if we could write our own algorithm and use that to guide shuffle in a way that feels more True Random or at least more enjoyable to discover songs you haven’t heard in a while, or songs you actually might like that you haven’t heard. In the middle of all this, I thought back to my design roots and daily UI challenges on Dribbble from 9 years ago and unearthed this mockup of a simple music player UI and decided I wanted to incorporate this into my design.

Turning ideas into code
To turn these ideas into reality, I used Cursor and started a blank directory and started a conversation with Claude 4:
We are starting from a blank project, but I have an idea for something to build.
I want to create a simple web page that has a spotify player on it, but we are going to create our own custom shuffle to be truly random.
I have a spotify api key to help us, but we can just use mock api data for now to get started.
I want to call this "True Shuffle".
Can you create an instructions file for us called "instructions.txt" with how you would provide instructions to yourself to refer back to as we build the project and stay on track through a project plan checklist.
Then, let's design a frontend ui prototype using tailwind as a design framework to get started and simulate any database and api setup synthetically.
Help me run npm install and npm start to test locally, and let’s set up git to allow version control
After this, Cursor began to build the project in front of me. The first time I saw this, my mind was blown for about a month straight. Now I’m used to it, but it’s still pretty fun to watch cursor build a project from a simple instruction. Of course, this wasn’t the end. This required much more iteration and improvement, but this got me up and running very quickly.
I’ve realized through many failures and AI rewriting my entire project enough at this point to know we need to always use github to control our versioning and always branch new features as we build them. This is something I learned as a software developer, but is crucial to implement in the vibe coding workflow.
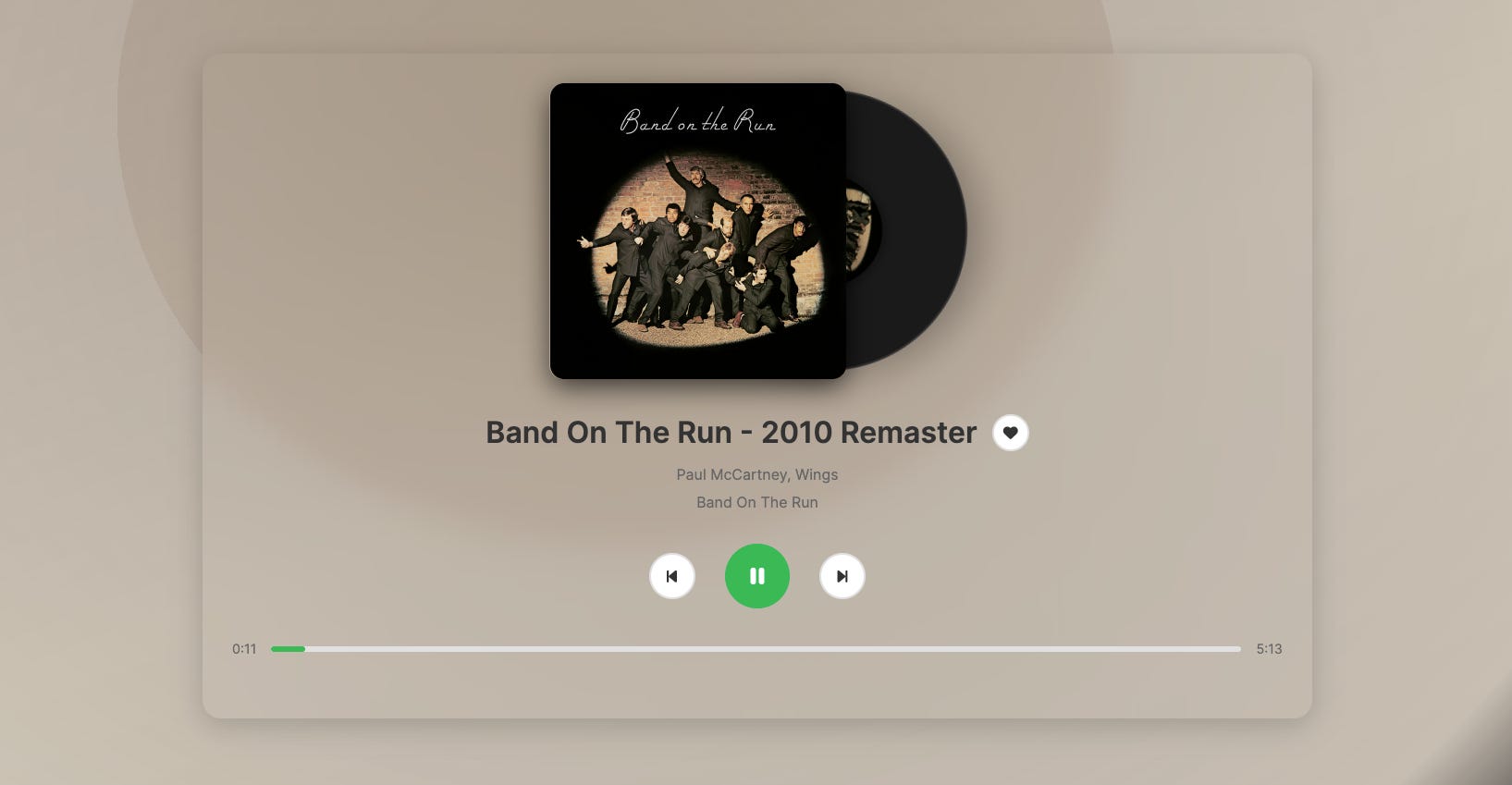
Over the course of a weekend, a functioning prototype was developed that uses a Spotify Developer API key, Google Cloud Run, and deployed to a live website:
This didn’t solve everything though. The first major issue is that Spotify’s Developer API can only be used for 25 users in development mode, and you must have 250k Monthly Average Users to get a production API key.
Additionally, upon algorithm refinement, it was clear that just creating a “True Shuffle” algorithm would not actually deliver an improved experience. I needed to write something that felt fun to listen to that delivered better results than the default results.
I developed new rules and tested algorithm variants based on:
1. Shuffle style selection
2. Year Range
3. Moods multi selection
4. Genre multi selection
5. Popularity of song slider
6. In my library vs not in my library shuffle mix settings
Which all provided interesting and more seemingly random results individually, but struggled to provide a better experience overall.
Then I tried being more prescriptive:
1. the first song played should be something in the user's liked songs that they have not played in over a year or next closest option.
2. while the first song plays, the pool of random songs to pull from should get populated by liked songs, songs in user made playlists, songs the user has listened to fully, and songs in their library.
3. using a random algorithm selection, choose the next song from the pool of available tracks.
4. keep the genres randomly chosen for each track
5. keep the popularity of the track randomly chosen
6. keep the year randomly chosen
7 keep the mood randomly chosen
8. continue selecting one of these options randomly to choose the next song.
9 do not repeat any songs played in Heard on True Shuffle already
10. do not play more than two songs by the same artist before playing 30 other artists or more
11. If you run out of a pool of songs to play, use this fallback method first: play songs of random years between 1960-2025; play songs between 30-70% popularity by artists I listen to that are not in my library
Still, the results were constantly still referring back to the default shuffle algorithm and playing the same artists over and over again that Spotify is biased toward. This was not what I wanted.
After further refinement, I kept a simplified version that has specific rules still similar to these 11 rules, but I realized I needed more data for Spotify to provide accurate recommendations. This brings us back to our initial problem: music has changed so rapidly that Spotify has an incomplete picture of my music taste. At this point I wondered about solutions. Clearly creating a lookalike audience and making recommendations to me is what Spotify was already doing and suggesting bad results of artists I was already aware of but chose not to listen to.
Then I had a realization: I had years of music data listening on Last.fm where I had Scrobbled all of my listening activity from 2008-2015, a massive catalog of data I could import into Spotify somehow. This task is one I have faced since converting to Spotify. It’s just too much to manually find and add. It’s too much for a person. But for AI…it’s perfect.
Last.fm offers a free API, and Spotify offers a free API in development mode. Could I use Cursor to vibe code a solution by writing an import script to collect all of the tracks I’d Scrobbled and add those songs to a playlist. The results were incredible. With a catalog of over 12,000 Scrobbled songs, this would be an impossible manual task, but with the python script and successful API connections, I was able to import 10,000 songs into a playlist from my past listening history in the order of most played from Last.fm.
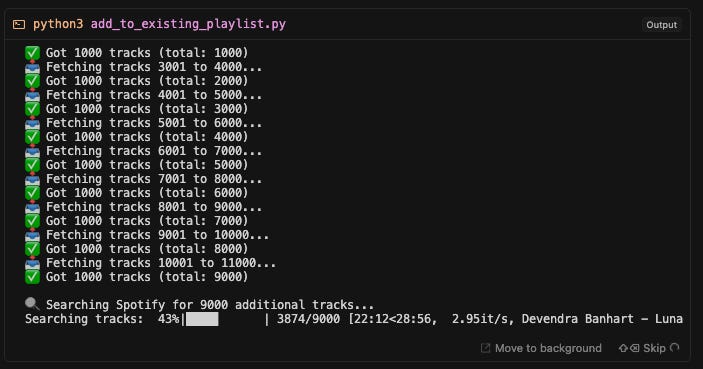
Here is a link to the public playlist that was generated with nearly 10,000 songs (Spotify’s playlist limit):
The issue still persists of: Spotify’s Developer API can only be used for 25 users in development mode, and you must have 250k Monthly Average Users to get a production API key. I am stuck at this point, so I ask you, who would the best 25 users be to grant access to in order to share trueshuffleradio.com with the world to use publicly?
Should I partner with a real radio station, gaming company, or even Anthropic to show as a feature of what Anthropic Claude 4 and 3.7 can do? Should I try and get access through Spotify directly as a specific edge case to their policy for API keys not being granted to individuals?
If you have ideas on ways to get a production API key, or would like to be granted access to the 25 available users, email me: vibecodingcommunity@gmail.com